


Mind and Iron: AI copyright hits a boiling point
OpenAI fires back, and activists aren't having it. Also Duolingo and fears of translation automation

Hi and welcome back to another episode of Mind and Iron. I'm Steve Zeitchik, veteran of The Washington Post and Los Angeles Times and chief lane operator of this rollicking bowling alley.
Every Thursday we bring you a range of stories, thoughts, interviews and insights on our fast-changing tech future, with an eye toward maintaining our humanity. (A project the tech companies…aren’t always focused on.) Please sign up here if you received this as a forward.
And please consider pledging to our cause here.
This week I thought would be devoted to predictions for the new year. But that was BEFORE the news went topsy-turvy. So we'll hold the predictions for the moment (the only certainty is chaos) to focus on that news.
On Monday OpenAI responded to the New York Times lawsuit. (Short version: “We did nothing wrong and in fact are bettering humanity.") Our coverage will give you the funky breakdown and tell you why you should care.
Over the past week researcher-activists have also stepped up their work showing how deeply embedded copyrighted material can be in AI models. So I called up one of the leading activists and asked what he saw as the future of these programs that generate text and images for us — whether this is the end of the ChatGPT party.
And this week popular language/best-way-to-trick-yourself-into-thinking-that-hour-on-your-phone-was-productively-spent app Duolingo revealed it had scuttled a whole bunch of its human staff for AI (which the remaining humans will now oversee). What this tells us about the future of translation apps and automation generally.
And what did people in 1974 think the year 2024 would look like? Paul Fairie, the University of Calgary professor skilled at understanding how people in the past understood the future, has some prime examples. (They were…not far off.)
First, the future-world quote of the week.
"OpenAI is in a very difficult position. They can try to cut deals with companies that are not motivated to make them. Or they can put out a significantly less worthwhile product.”
—AI activist Gary Marcus, on how a New York Times lawsuit could change everything with AI
Let's get to the messy business of building the future.
IronSupplement
Everything you do — and don’t — need to know in future-world this week
OpenAI says they’re just trying to save humanity; Duolingo turns to the machines; what 2024 looked like 50 years back
1. THE NEW YORK TIMES LAWSUIT AGAINST OPENAI IS THE FIRST of what will likely be many legal challenges to how we’re building these thinking machines — a canary in the coal mine of the Generative AI era.
On Monday the mine operator showed how they plan to greet the birds.
OpenAI responded to the Times’ copyright-infringement suit with a strange blog post — an exercise in at once solicitousness and defiance. If you recall, the Times alleges that OpenAI can’t put their work into a training blender for products like ChatGPT and Dall-E without permission/payment — a kind of anti-Napster argument. That taking millions of articles to “train” a model so that ChatGPT can crank out fully realized blocks of texts isn’t really fair use of these articles.
OpenAI’s essential response is: "We are actually the good guys here. Not that we need to be."
As the company put it:
"The principle that training AI models is permitted as a fair use is supported by a wide range of academics, library associations, civil society groups, startups, leading US companies, creators, authors, and others...That being said, legal right is less important to us than being good citizens."
OpenAI then cited an opt-out being given publishers (which came many months late and is not easily executed, but another matter.) “Training is fair use, but we provide an opt-out because it’s the right thing to do.”
This whole argument is a bit weird, not just legally but tonally. It feels like a bully who, when he's done pushing you around, wants you to really like him — Biff Tannen crossbred with Sally Field. I mean, be a good buy or be a bad guy. But be one of them. If you're going to swipe someone's lunch money you don't get to revel in their accolades about how wisely you spent it.

So what’s going on here? Why does the company want to be so Lomanishly well-liked? Well, because OpenAI can’t afford to be the bad guy. Like, financially. They need other content creators NOT to sue them. And they need customers to keep signing up for ChatGPT and Dall-E in record numbers. At some point Napster in the public imagination went from "whee, free music is fun," to "um, stealing all this music without paying for it kind of doesn't feel right." OpenAI really doesn’t want to follow the same arc.
(For which arc they will follow according to one of the sharpest eyes in the space, see our Q&A with NYU prof and New Yorker contributor Gary Marcus below.)
What OpenAI wants to convince us of is a delicate combination of both the idea that they don’t need creators’ blessing and the fact that they deserve it anyway — that they are, to put it more diametrically, a friend to the creative people they are trying to replace.
Will consumers/clients buy it? That's the $80 billion question. (Or whatever OpenAI is currently valued at.) I suspect a lot of individual users aren't seeing enough of AI’s appeal in their daily lives to feel this tension one way or another; this isn't like getting every Prince or Madonna song for free. But give it time. Once AI Assistants come into play — once the models can fully whip up every backyard-barbecue invite and PTA letter we’ll ever need — we'll start feeling the pull a lot stronger.
Never mind once these programs delve deeply into video, allowing anyone who wants to produce their own “Star Wars” and Marvel content to do so. This is why the stakes are so much higher than even the suit and its familiar language of copyright-infringement suggests — why it’s about more than just getting a product for free. Napster allowed us all to be easy consumers. AI generators allow us all to be easy creators.
And then the question will really tug: Does it matter where all the tools that produce this trusty AI Assistant come from? Does it matter that the material that allows us to create like James Cameron comes, unknowingly, from James Cameron himself?
Well if you care about copyright and not taking stuff that doesn’t belong to you, it does. If you do but not enough not to use it, as many of us Napster fiends did, well, that’s why we have legal standards. And though it will take a long time for the Times’ and other lawsuits to wend their way through the courts, it is good for that wending to happen. The sooner we start the reckoning the sooner we get to the resolution.
[Btw, OpenAI in the post argues that "regurgitation" — i.e., the massive blocks of ChatGPT output text that are indistinguishable from the original stories — is “a rare bug that we are working to drive to zero.”
Now, it’s true that regurgitation isn’t common — it probably happens only a small percentage of the time — and the lawsuit was being a little shameless in foregrounding it. But don’t be fooled by OpenAI’s response, which is a red herring at best and a straw man at worst. A model doesn’t need to regurgitate to be problematic. The real issue — legally and probably ethically — is not how many of the exact words ChatGPT replicates. It’s how much the NY Times stories directly enable the final product. And it’s clear the Times stories enable lot. If they didn’t, why would OpenAI be fighting so hard to use them?]
On the same day that OpenAI published its retort, The Daily Telegraph reported that the Sam Altman company recently lobbied the House of Lords in the U.K., suggesting that it needs a copyright exemption to continue doing business. "It would be impossible to train today's leading AI models without using copyrighted materials,” the firm said in a submission to the body. Without such an exemption, OpenAI wrote, the company would be unable to “provide AI systems that meet the needs of today's citizens."
It’s a startling request with a wild assumption at its core — that such a dominant AI system needs to be created in the first place. OpenAI for some reason believes that copyright, an age-old system designed to protect and foster creativity, must bend to the needs of AI, a new system with numerous uncertain effects, instead of the other way around.
Big tech companies are saying it's OK for them to build the models that will change our lives on the backs of the people who actually did the work. Venture capitalists and other investors don't seem to mind. The voice of our own conscience, though, just might.
OpenAI says not to listen to this voice. After all, they didn't. And they're the good guys.
[The Daily Telegraph, The Guardian and OpenAI]
2. WATERING THE PLANTS OF A FRIEND WHO’S OUT OF TOWN THIS WEEK, AN AMUSING EVENT WENT DOWN.
A person doing work around their house who happened to speak a language other than English urgently pulled out a phone and showed me the words on the screen.
“I have finished my homework. Is it ok if I go?”
Now, this person was at least 35. Also, I had not assigned them any homework.
What they were using was a translation app, one that (understandably?) had translated “work around the house” from their native language into “homework” in English.
I didn’t get a chance to ask them what app they were using before I said of course they could go (but please don’t forget to study for the math quiz). The moment, however, did crystallize a story that broke later that day: the language app Duolingo said enough with these humans, we’re moving to AI.
Well, they didn’t say that exactly. But they replaced a number of people who had long been working with them — ten percent, according to the firm — with AI systems.
A member of one of the shaken-up teams said that he and another long-term worker were being laid off, with only two people left on the team. And their new job was to oversee the AI.
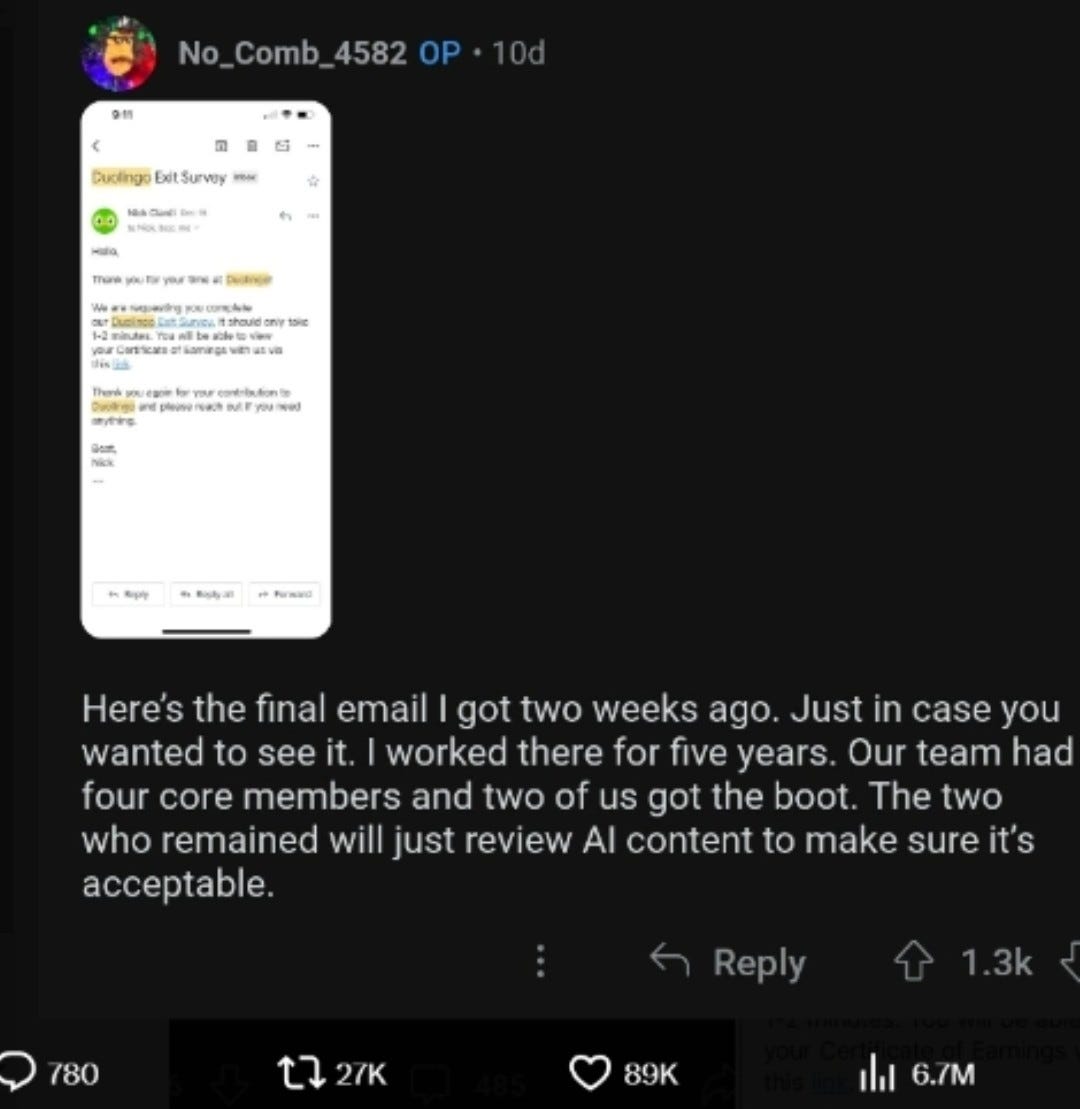
Duolingo has become massively popular (though how much it’s teaching us remains an open question). But monetizing that popularity apparently requires not spending on the people who create and maintain the system. Duolingo also recently added a feature incorporating ChatGPT that allows users to converse with a chatbot, which corrects a user’s mistakes. Language tutoring, thy future is robot.
“Generative AI is accelerating our work by helping us create new content dramatically faster,” Duolingo chief executive Luis von Ahn recently wrote to shareholders.
From an automation standpoint, all this isn’t really news. Duolingo is hardly the first company to trim staff this month, let alone in the year ahead. Translation is one of many, many areas that penny-pinching/tech-drunk execs believe can be automated, embracing any drop in quality as an acceptable price for saving salaries.
In fact this is particularly likely in the language realm. Basic language-translation is fundamentally a challenge of data sets and speed, both skills where microprocessors have long lapped brains. I mean, “Large Language Models” — it’s right there in the name. So whether in programming or translating, get ready for a lot more AI in our language apps. (Higher-level use of nuanced language is of course another matter.)
Yet news of automation in this space also hits harder. Because speaking a second language, never mind mastering it, is a deeply human experience; every nuance conveyed today that couldn’t be delivered yesterday is a small triumph of our humanity. And now one of the entities that helps with all that is saying, eh, let the machines do all the helping.
As AI skeptic and Hollywood visual artist Reid Southen put it (more on him below), “This is the world we're creating. Removing the humanity from how we learn to connect with humanity.”
Or as the illustrator Emmy Cicierega noted, “Duolingo disrespecting the deep nuance of culture and language to just leave it up to AI is wretched.”
Hard to argue with all of that. This feels disturbing. Not to mention awkward. AI helping us learn a new language or translate in real time is still far from fluid; we’re a long way from Star Trek’s Universal Translator. My experience at my friend’s house echoed a hilarious-poignant moment a few years ago when, waiting on an unusually long line to check into a Las Vegas hotel, a non-English speaker in front of me showed me a question in English on a translation app on his phone and gestured to me to speak into his phone in response.
He’d then read what was on the screen, speak back into it and showed me what it produced. By the time we got to check-in we had learned what the delay was about, what work events each person was in town for and whether there would be any crossover. At least I think we learned that. Pretty cringe.
Still, simple lamentation may not be the right reaction here either. Sure, language apps, especially those governed by AI, are a slippery beast. They are predicated on the idea that machines can substitute for human connection — for the intangible beauty of learning how others communicate. But amid the kvetching we should probably remember how the emergence of these systems has also had a bridging effect.
Without the easy accessibility of language apps, fewer people would take the leap of learning another language. (Duolingo now has 24 million (!) daily active users.) And without the availability of software that can quickly give a rough translation, many of us might not try talking to a stranger at all. The worker in my friend’s house would still be working, and the Vegas visitor and I would have suffered that line in sad atomizing silence. No matter how much AI is used to do the translating, it can’t elide the fact of who it’s translating for: two humans who want to better understand each other. And as these programs proliferate (and get better), we’ll be able to do more of that.
It’s doubtless a shame that AI is now being used to fill the gaps on something so fundamentally human as language learning. But in grieving this latest step in our growing mechanization, it may also be worth taking a second to bask in the hug they come with: that such programs exist in the first place.
[CNN and Bloomberg]
3. LAST WEEK WE TOLD YOU WHAT THE PEOPLE IN 1924 THOUGHT 2024 WOULD LOOK LIKE.
This week we go back to the well, but traversing 50 years instead of 100. Paul Fairie, the University of Calgary professor who dug up those headlines from 1924, has this doozy of an item from 1974.

Amazingly, at least one has already come to pass — cochlear implants have become extremely common. The procedure gained in popularity throughout the 2000’s, and by 2021 nearly 800,000 people worldwide had received them. Way ahead of schedule on that one, Dr. DeBakey would be happy to know.
Machines determining baseball strategy isn’t * entirely * here yet; coaches still use plenty of human intelligence on the sideline. But computer models have of course been employed in front-offices for decades, ever since Billy Beane began using them to make personnel decisions for the Oakland A’s in the early 2000’s. And analytics now determine a slew of in-game decisions across football, baseball and hockey. The coach-computer takeover is well underway.
As for the moon, well, that one takes longer, the whole lack-of-atmosphere thing. But more and more countries want to travel there, and one of the world’s richest men preaches an unshackling of these Earthly chains. So Neil may get his wish. Just might have to be on the 75th or 100th anniversary.
IronClad
Conversations with people living the deep side of tech

How screwed is screwed for ChatGPT?
A talk with Gary Marcus
The image-generation tool Midjourney bills itself as “an independent research lab exploring new mediums of thought and expanding the imaginative powers of the human species.”
Its opponents think a shorter descriptor suffices: thievery.
Midjourney is one of several services that has come under fire from activists who say that branded characters can be generated on these platforms with surprising ease. No need to break the model, nor do the stars have to align, for Marvel, Star Wars and other beloved figures to pop up when a user asks for an image, thus enabling copyright infringement.
One of the leading figures showing the way on this is AI expert and NYU professor Gary Marcus. An acclaimed author and AI entrepreneur, Marcus has been intent in recent months on showing how these supposedly sophisticated syntheses are too often just illegal rip-offs of existing content.
Together with Hollywood visual artist Reid Southen, Marcus recently published a story in the engineering magazine IEEE Spectrum on this subject. (You can see their damning findings here.) And ever since the New York Times filed a lawsuit, he’s been vocal in his projection that OpenAI and its competitors will need to radically adjust course.
With copyright at the center of future-world news this week, I caught up with Marcus to get his take on both what’s happening and where he thinks things are going. The conversation has been lightly edited for brevity and clarity.
Mind and Iron: So the Times lawsuit feels like a turning point — culturally if not legally. A lot of people who didn't quite get what the fuss was about now understand that there are some serious copyright stakes here.
Gary Marcus: I think the lawsuit is pretty solid and woke some people up. And hopefully that will wake some more people up. It counters some of the argument that this [alleged infringement] is a little minor thing. No, it's not. It's pretty common. This is an interesting moment in the culture. A year ago [when ChatGPT was first released] people just used it however they wanted. And now they’re paying attention in a different way.
M&I: How much does this cultural shift affect OpenAI's business? Will it stop people or companies from using the service?
GM: A lot of companies have tried to use it but they can't because it hallucinates. Now they will see there's another problem — the costs of violating copyright could be really high. So they may not use it for that reason.
M&I: And if you're a big company you might even be thinking about suing.
GM: Definitely. I would not be surprised if Nintendo or Disney filed a lawsuit too.

M&I:: I assume that OpenAI is going to start trying to cut deals to head this off and secure rights. Will publishers make those deals?
GM: I think publishers mostly won't sign deals because they'll want to see how the Times lawsuit shakes out. They'll say ‘you're offering me $5 million but the lawsuit could say my content is worth $100 million.’ So they'll hold off.
M&I: And that kind of stops the models from being trained, right? Or does OpenAI keep right on training and rely on their belief that everything they're doing is fair use?
GM: It’s interesting to see if they continue to do that. They could, but then a jury could later say ‘your infringement was really blatant, you kept doing this even when it was clear this was all copyrighted material.’ And that will run the damages up. But on the other hand we also know that OpenAI can’t train these models without the copyrighted material — they’ve said as much to the House of Lords. So they’re in a very difficult position.
M&I: Basically a rock and a hard place.
GM: Yes. They can try to cut deals with companies that are not motivated to make them. Or they can put out a significantly less worthwhile product.
M&I: So you don't think they believe their fair-use argument — they don't really think that they could go right on training their models without permission and a jury will let them off the hook.
GM: No, I think they know that's a Hail Mary. They’re hedging their bets in case they can’t make deals.
M&I: One of their main defenses is that these '“regurgitations” that the Times lawsuit cites are not common. That the paper had to try very hard to get ChatGPT to produce full copies of text, the kind of thing most users won’t do, and even then it didn’t happen so often. That it’s just a bug, essentially. Yet you showed with your new work with Reid Southen how easy it is to get image generators like Midjourney and OpenAI’s Dall-E to crank out copyrighted material — “visual plagiarism,” you call it. So how strong is the AI companies’ case on this front?
GM: They’ll say all that, and then the NY Times or Disney will say ‘can you prove you never produce something that is derivative and always produced something that is transformative?’ And they can’t say that under oath; they can just say it doesn’t happen that often. Then the NY Times or Disney will say ‘even if it just happens three percent of the time, you serve up billions of queries, let me run my calculator, you owe us a lot of money.’ Notice also that OpenAI didn’t say anything in the blog post about the visual stuff — I think it’s going to be much harder to defend that.
M&I: Where does this all shake out, do you think — can OpenAI and others actually sign the deals needed to make these programs effective? Will artists get paid?
GM: Independent companies like Midjourney are in a lot of trouble because they don’t have the money for all this. OpenAI won’t fold because they have Microsoft backing them up so they can survive a lot of litigation. And yes eventually I do think it’s conceivable that all this could be properly licensed. That’s what happened with Napster — other versions came through the ashes and now there’s streaming and licensing. If Apple wants to do this they’ll cut a deal. Apple cuts deals with every music publisher. Netflix spends however many billions on content. It’s not like OpenAI can’t license stuff. The weird thing is asking for special pleading.
M&I: And the artists?
GM: Right now they’re not getting their fair share. In the end artists will get something. It might be pennies on the dollar. But it’s not tenable or reasonable that artists get nothing. Deals with be made.
M&I: So when all is said and done, will these models be available — and useful — to us consumers? Like, give me the view of what our interaction with AI looks like in two or three years, after all the copyright dust settles.
GM: I think so. I think every company will have to figure out what they’re comfortable with. Like, Disney might say you can use Marvel characters but you can’t make movies with them, and that will be built into their licensing deals. But it’s definitely all going to be more expensive. Because people [at OpenAI and its rivals] have been doing this until now by not paying for the raw materials. Now they’re going to have to pay for the raw materials, one way or another. And of course that cost will be passed on to the consumer.
The Mind and Iron Totally Scientific Apocalypse Score
Every week we bring you the TSAS — the TOTALLY SCIENTIFIC APOCALYPSE SCORE (tm). It’s a barometer of the biggest future-world news of the week, from a sink-to-our-doom -5 or -6 to a life-is-great +5 or +6 the other way. Last year ended with a score of -21.5 — gulp. But it’s a new year, so we’re starting fresh — a big, welcoming zero to kick off 2024. Let’s hope it gets into (and stays) in plus territory for a long while to come.

OPENAI RESPONDS TO THE TIMES LAWSUIT, BUT BIZARRELY/UNPERSUASIVELY: It doesn’t help their case. +2
DUOLINGO THINKS MACHINES ARE BETTER THAN HUMAN TRANSLATORS : Ugh. -3
THE WORLD HAS ACTUALLY ACHIEVED SEVERAL OF THE ADVANCES EXPERTS PREDICTED IN 1974: +2.5